

 Stijn Mommersteeg
Stijn MommersteegUp to this point, not a single line of code has been written. And that’s precisely how we like it. It’s sometimes tempting to start building right away, but in reality it’s important not to bypass the early design phases. Without a clear value proposition and tested user flows, the chances of building something nobody is waiting for, are just too damn big. Now we’ve finished the ground work, we get to apply our insights and designs to the real thing. Let’s build this app!
Nerd alert (skip if you're not a nerd)
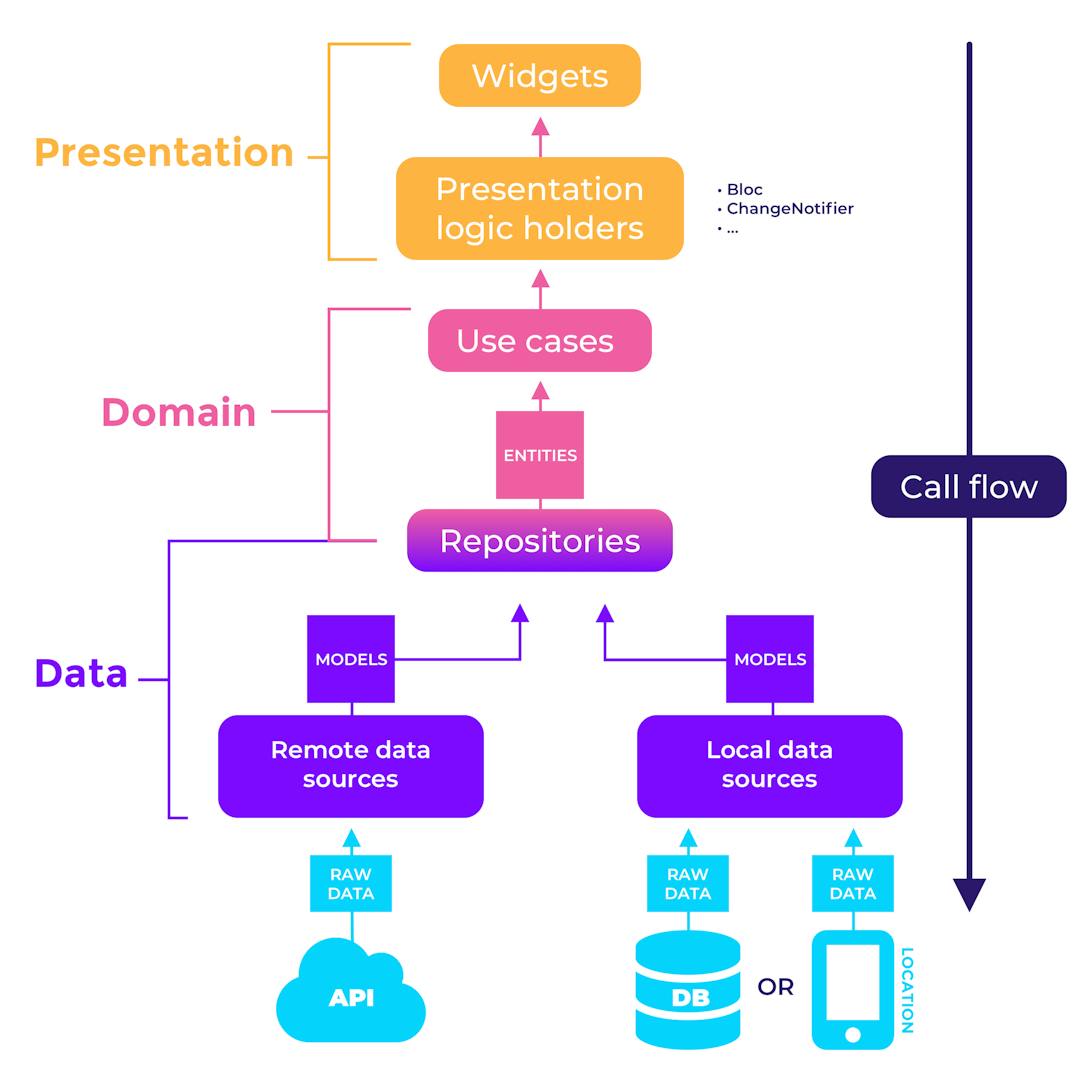
So let us get unapologetically detailed here for a moment. The app was built in Dart using Flutter 2.2 and upgraded to 2.5 shortly before release. We worked with the TDD approach (Test Driven Development) and used clean architecture to structure our code and apply separation of concerns. We combined this with the Bloc pattern for state management and separated our business logic from the view layer. Error tracking is done in a self-hosted Sentry instance.
The editor Stijn used: VScode with, of course, the Flutter plugin.
To Scrum or not to Scrum
Scrum is a popular way of work for software development. And for a lot of good reasons (but that calls for a blog on its own 😉). Even though the Holy Scrum Guide removed strict rules on team size (used to be 3 - 9 people) and now only says it’s “typically 10 or fewer people”, there is much to say for not going all out Scrum in a team with just 1 developer and 1 designer. Most of Scrum's principles revolve around managing relationships between team members, but with a team that’s too small, it might create more overhead than needed.
So we opted for the more pragmatic approach: take useful concepts from the Agile ways, but leave out the unnecessary. For example, we did not do any daily standups or retrospectives: the team was too small and too short-lived respectively. We did keep an ordered backlog (in the form of Gitlab tickets), had a product owner involved, and worked with sprint demos. Because predicting our velocity was hardly relevant (and nearly impossible for the short duration of the project anyways), we didn’t do any ticket sizing and had slight variations in sprint length. The ticket refinement process focussed mostly on clearing up unclarities. All this resulted in an agile way of working, without being bogged down by unnecessary overhead.

Bug-less code
Even in a small application, you can have thousands of lines of code. In the case of fdtrck 5627 lines of Dart code to be exact. That amounts to well over half a million characters.
A single mistype in any of these characters has the potential to crash the entire application. Let that sink in…
Just to demonstrate the sensitivity of mistypes, I’d like to take you back to a dark day in tech history: July 22nd, 1962. On this day NASA’s Mariner 1 spacecraft was launched to collect a variety of data from Venus. Its flight lasted only a whopping 293 seconds, after which erratic behavior of the Mariner 1 led the operator to issue a self-destruct. Investigation into the problem led to a painful conclusion: a single missing hyphen (a ‘-’) in the code caused the crash. At some $554 million dollars, that’s an awfully expensive typo.
So how do we prevent astronomical mishaps like these? Even in a small code base like fdtrck we can’t guarantee code to be free of typos, let alone more complex bugs. Developers are human after all. AI-generated code seems to be around the corner, but it doesn’t solve anything today. Our only options right now are to focus on minimizing the number of bugs created and maximizing the number of bugs we discover.
For fdtrck, as with all of our projects, we used automated testing. This usually helps very well with finding one of the more nasty sorts of bugs: you change something and something else breaks. The tests are being run, automatically, every time we push new code. We used Bitrise for that, which is so cool that we’ll dedicate the next blog in this series entirely to this. The TDD (Test Driven Development) really comes into play here.
Furthermore, we use a lot of tools to help write good code easier as we type (pretty much like autocorrect or spellchecker). Lastly, we ask random strangers to test our apps. Usually, users manage to break apps (unintentionally) in ways you can’t think of yourself.
In conclusion
When the project scope is fully clear, it is time to start building. The key to quality code does not necessarily depend on the choices for a particular technology, but rather in the process of development. By using a slimmed-down version of Scrum, we were flexible and fast during development and could focus on creating meaningful features. We used automated testing and useful tools that help keep bugs to a minimum, but in the end, we always test with genuine people, because they always find a way to use your app in unimaginable ways.

 Martijn Imhoff
Martijn Imhoff
 Bas de Vaan
Bas de Vaan
 Katja van Weert
Katja van Weert



